
티스토리 뷰
대량의 데이터를 삽입하는 상황이 생겼습니다.
초창기에는 JPA Save함수를 반복문을 통해 호출해서 저장하게 구현을 했는데요.
처음에는 괜찮았으나, 삽입 할 데이터가 점점 많아지면서 삽입 시간이 굉장히 오래 걸리게 되었습니다.
그래서 최적화에 신경 쓰게 되었는되었습니다.
자바에서 데이터를 insert하는데 가장 방식은 Spring batch를 이용하여 JPA없이 Writer를 쓰는게 제일 빠릅니다.
(관련 글을 추후 포스팅 예정...)
본 포스트에서는 Spring boot에서 JPA를 사용하여 트랜젝션을 최적화하여 속도를 향상시키는 방법으로 알아보겠습니다.
1. 잦은 save 함수 호출의 문제점
@Transactional
@Override
public <S extends T> S save(S entity) {
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}JPA save함수 소스코드입니다. 함수에 @Transactional이 선언되어있는 것을 볼 수 있습니다.
이 함수가 호출될 때 트랜잭션이 시작되고, DB에 데이터가 정상적으로 삽입이 완료되면 트랜잭션이 종료 됩니다.
만약 10만 개의 데이터를 삽입한다고 가정한다면, 10만 번의 save함수가 호출이 되겠고,
이는 10만번의 트랜잭션이 시작됐다가 종료된다는 뜻입니다.
즉, save 함수를 호출할 때마다 트랜잭션이 실행되기 때문에 이에 대한 오버헤드로 삽입 속도가 굉장히 느려지게 됩니다.
2. @Transactional
최적화 방법은 간단합니다. 여러 번 호출되는 트랜잭션을 하나로 묶는 것이죠.
save 함수가 호출 되는 Controller 혹은 Service 구현부에 @Transactional을 선언하거나,
삽입할 데이터들을 List로 묶어서 saveAll 함수를 호출하는 것입니다.
saveAll함수에는 @Transactional이 선언되어 있으며, List를 순회하면서 save를 호출합니다.
@Transactional
@Override
public <S extends T> List<S> saveAll(Iterable<S> entities) {
Assert.notNull(entities, "Entities must not be null!");
List<S> result = new ArrayList<S>();
for (S entity : entities) {
result.add(save(entity));
}
return result;
}
위 둘의 공통점은 save함수보다 더 상위에 @Transactional가 선언되어있다. 라는 것입니다.
더 상위에 @Transactional 호출되어 있다는게 무슨 의미가 될까요?
Spring에서는 @Transactional의 선언 위치나 설정에 따라 트랜잭션 동작이 달라지게 됩니다.
@Transactional의 기본 전파 전략은 REQUIRED입니다. 이 전략은 현재 트랜잭션이 없을 경우 새로 생성하고, 이미 시작된 트랜잭션이 있다면 새로 만들지 않고 기존 트랜잭션에 참여하는 전략입니다.
즉, save함수가 호출되는 Controller 혹은 Service, 함수에 @Transactional이 선언되어있지 않다면, 이미 시작된 트랜잭션이 없기 때문에 save 함수가 호출될 때마다 계속 트랜잭션이 시작되고 종료되는 것입니다.
반대로 선언이 되어있다면, Controller 혹은 Service가 호출 될 때, 트랜잭션이 시작이 되고, 그 안에서 호출되는 save함수는 이미 시작한 트랜잭션안에 포함되어 있기 때문에 새로 생상하지 않고 기존 트랜잭션에 참여합니다.
saveAll 함수도 마찬가지로, saveAll 함수가 호출되는 시점에 트랜잭션이 시작되고, 그 안에서 순회하면서 호출되는 save함수는 기존에 시작된 트랜잭션에 참여하므로 하나의 트랜잭션으로 묶이게 됩니다.
그러면 @Transactional를 선언해서 무조건 트랜잭션을 하나로 묶으면 되나?
이는 절대 아닙니다.
예를 들어, Controller에 1만 개의 데이터를 삽입하고, 특정 데이터는 다시 가공하여 업데이트를 하고, 특정 데이터의 일부를 지우는 API가 있다고 가정해봅니다.
만약 이 API에 @Transactional를 선언하게 되면, 일련의 모든 과정들이 하나의 트랜잭션으로 묶이게 됩니다.
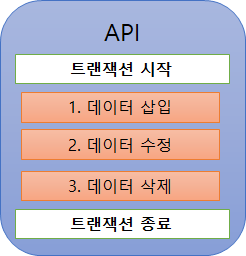
하나의 트랜잭션으로 묶이게 되면 트랜잭션 시간이 길어지게 되며, 해당 시간 동안 다른 곳에서 데이터에 접근할 수 없기 때문에 딜레이가 발생합니다. 그리고 API 로직이 복잡해진다면 데이터 관리가 어려워집니다.
이러한 문제는 전파 전략(propagation)과 격리 수준(isolation) 설정을 통해 해결할 수 있습니다.
물론 시스템 구조상 하나의 트랜잭션으로 묶는 경우도 있습니다. 결제와 같은 중요한 시스템에서는요.
하지만 굳이 트랜잭션을 하나로 묶어도 되지 않는다면 이러한 경우는 피하는 게 좋습니다.
3. 하나의 트랜잭션으로 묶고는 싶고, 시간은 길어져서 문제다...
트랜잭션을 하나로 묶어서 대량의 데이터를 삽입하는데 속도가 굉장히 빨라졌습니다.
30만 개의 데이터를 삽입하는데 20분에서 10분으로 줄었습니다.
그러나 큰 문제는 30만 개의 데이터가 삽입이 끝날 때까지 하나의 트랜잭션이 끝나지 않고 긴 시간 동안 유지되는 겁니다.
데이터 삽입하는 동안에 이 데이터로 접근이 필요 없다면 트랜잭션이 길어져도 상관없겠지만, 보통은 그렇지 않기 때문에 트랜잭션이 길게 유지되어 다른 곳에서 접근이 못한다면 이 또한 문제가 되겠죠.
격리 수준을 낮추는 방법이 있겠으나, 이는 여기서 다루진 않겠습니다.
가장 간단한 방법은, 아래 코드와 같이 일정 단위로 묶어서 saveAll 함수를 호출하는 것입니다.
public void saveAllWithDivide(List<Insert> list) {
List<Insert> tmp = new ArrayList<Insert>();
list.forEach(i -> {
tmp.add(i);
if (tmp.size() == 100) {
repo.saveAll(tmp);
tmp.clear();
}
});
}
30만 개의 데이터를 100개 단위로 트랜잭션을 구성하여 삽입을 한다면, 총 3,000번의 트랜잭션이 발생하여 약간 삽입 성능이 감소되겠지만, 트랜잭션이 계속 유지되고 있지 않기 때문에 다른 곳에서 데이터 접근이 가능합니다.
4. 성능 비교
10,000개의 데이터를 4개의 테스트 방식으로 나눠서 삽입했을 때 걸린 시간입니다.
각 케이스마다 2회씩 테스트를 진행하였습니다.
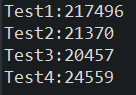
Test 1: @Transactional 선언 없이 save 함수 호출
- 1차:217.496초
- 2차:224.056초
Test 2:@Transactional 선언 후 save 함수 호출
- 1차:21.370초
- 2차:21.574초
Test 3: saveAll 함수 호출
- 1차:20.457초
- 2차:21.006초
Test 4: 100개 단위로 나누어서 savaAll 함수
- 1차:24.559초
- 2차:24.251초

5. 결론
테스트 결과를 확인해보면, 트랜잭션으로 인한 오버헤드가 어마어마 하다는 것을 알 수 있습니다.
Test 2와 Test 3은 원리적으로 동작이 같기 때문에 성능이 거의 동일하게 나왔습니다.
Test 4의 경우 100개씩 총 100회의 트랜잭션이 수행 되었겠네요.
정답은 없겠으나, 프로그램 설계나 구조에 맞게 트랜잭션을 적절히 구성하는 것이 가장 올바른 것 같습니다.
'Java > JPA' 카테고리의 다른 글
| [Spring boot] JPA Dialect(방언) 설정에 관하여 (3) | 2020.11.11 |
|---|---|
| Spring JPA Multiple Databases 설정 (0) | 2020.04.13 |
| JPA (Java Persistence API) 이란? 기본 개념 및 이론 정리 (1) | 2019.08.01 |
- Total
- Today
- Yesterday
- 리스트
- C
- Google Drive SDK
- 구글 드라이브
- 구글 드라이브 개발
- C++
- 후지필름X100V
- 링크드리스트 클래스
- ssd추천
- 후지필름
- 후지필름 일렉트로닉
- 구글 드라이브 API
- ssd비교
- ssd성능
- 삼성ssd
- 샌디스크ssd
- SDK
- X100v
- 리스트 클래스
- 리스트 소스 코드
- 링크드리스트
- SSD
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |